
A data pipeline is a method for ingesting raw data from multiple data sources, transforming it, and then transferring it to a data repository, such as a data lake or data warehouse, for analysis.
Data is typically processed before it is stored in a data repository. This includes data transformations like filtering, masking, and aggregating, which ensure that data is properly integrated and standardized. This is especially crucial when the dataset will be stored in a relational database. This sort of data repository has a predetermined schema that needs to be aligned—that is, data columns and types must match—in order to update old data with new data.
2. Types of data pipelines
There are various sorts of data pipelines, each designed for a certain task and platform. Common types include:
Batch processing pipelines
Streaming Data Pipelines
Data Integration Pipelines
Cloud-native pipelines.
Batch Processing
1. Batch processing
The introduction of batch processing was a major step toward creating dependable and scalable data infrastructures. The batch processing algorithm MapReduce was patented in 2004 and then implemented into open-source systems such as Hadoop, CouchDB, and MongoDB.
As the name implies, batch processing loads “batches” of data into a repository at predetermined intervals, which are usually planned during off-peak business hours. This ensures that other workloads are not disrupted, as batch processing jobs typically operate with enormous amounts of data, which might burden the overall system. When there isn’t an immediate requirement to evaluate a specific dataset (for example, monthly accounting), batch processing is usually the best data pipeline option. It is more connected with the ETL data integration process, which stands for “extract, transform, and load.”
2. Streaming Data
Unlike batch processing, streaming data pipelines, also known as event-driven architectures, process events constantly from a variety of sources, such as sensors or user interactions inside an application. Events are processed and examined before being either stored in databases or routed downstream for additional research.
Streaming data is used when data needs to be updated continuously. Apps or point-of-sale systems, for example, require real-time data to update product inventory and sales history; this allows vendors to advise customers whether a product is in stock or not. A single action, such as a product sale, is referred to as a “event,” whereas related events, such as adding an item to the checkout, are often linked together as a “topic” or “stream.” These events are subsequently routed through messaging systems or message brokers, such as the open-source Apache Kafka.
3. Data Integration Pipelines
Data integration pipelines focus on combining data from several sources into a single, cohesive perspective. These pipelines frequently include extract, transform, and load (ETL) procedures, which clean, enrich, or otherwise modify raw data before putting it in a centralized repository like a data warehouse or data lake. Data integration pipelines are critical for managing different systems that produce incompatible formats or structures. For example, a connection can be created to Amazon S3 (Amazon Simple Storage Service), a service provided by Amazon Web Services (AWS) that allows for object storage via a web service interface.
4. Cloud-native data pipelines.
A modern data platform consists of a set of cloud-first, cloud-native software products that allow for the collection, purification, transformation, and analysis of an organization’s data to aid decision making. Today’s data pipelines have grown in complexity and importance for data analytics and decision-making. A modern data platform increases trust in this data by ingesting, storing, processing, and converting it in a way that provides accurate and timely information, decreases data silos, allows for self-service, and enhances data quality.
3. Data pipeline architecture
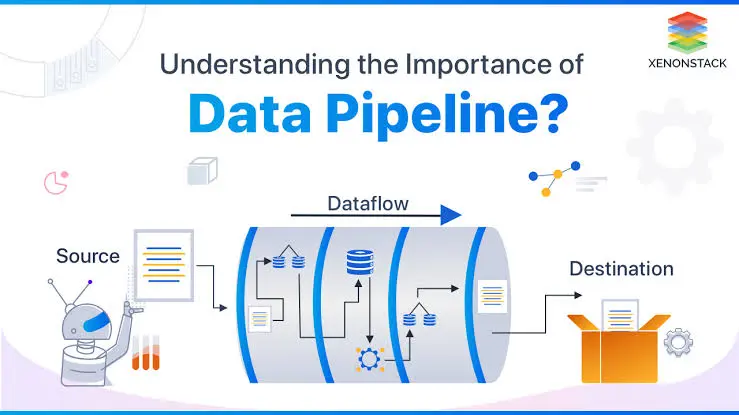
1. Data ingestion: Data is collected from a variety of sources, including software-as-a-service (SaaS) platforms, internet-of-things (IoT) devices, and mobile devices, as well as organized and unstructured data. Within streaming data, these raw data sources are sometimes referred to as producers, publishers, or senders. While organizations might choose to extract data only when they are ready to analyze it, it is preferable to first store the raw data in a cloud data warehouse provider. This allows the company to update any previous data as needed to make changes to data processing jobs. During the data intake process, different validations and checks can be performed to verify data consistency and accuracy.
2. Data transformation: In this step, a series of processes are run to convert data to the format required by the destination data repository. These jobs use automation and governance for repeated workstreams, such as business reporting, to ensure that data is cleansed and transformed consistently. For example, a data stream may be in nested JSON format, and the data transformation stage may attempt to unroll that JSON and extract the key fields for analysis.
3. Data storage: The modified data is then stored in a data repository, where it may be accessed by multiple stakeholders. Within streaming data, this modified data is commonly referred to as consumers, subscribers, or recipients.
4. Data pipeline vs. ETL pipeline.
You may notice that certain phrases, such as data pipeline and ETL pipeline, are used interchangeably in discussion. However, consider an ETL pipeline to be a subtype of data pipelines. Three fundamental features distinguish the two types of pipelines.
ETL pipelines follow a predefined order. As the name suggests, they extract data, transform it, and then load and store it in a data repository. Not all data pipelines must follow this sequence. In reality, ELT (extract, load, transform) pipelines have grown in popularity as cloud-native solutions enable data to be generated and stored across different sources and platforms.